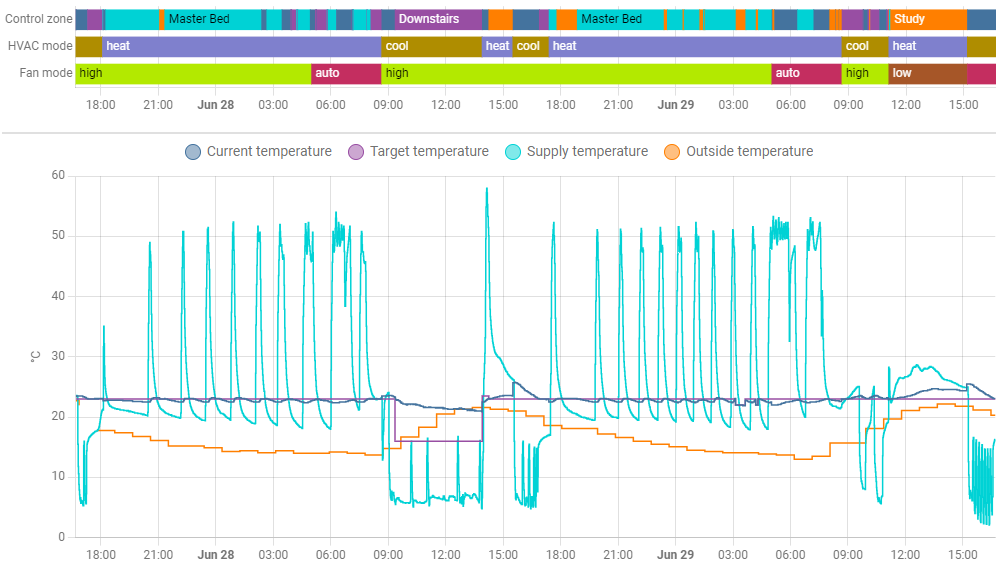
Matter and Thread offer many benefits, with standardised interoperability, local-only control, built-in security, multi-admin, and IPv6 support — helping drive IPv6 adoption and development skills.
Several devices have now launched, and I have tried out a few of the available devices with Google Home and Home Assistant, however these are early days, and feature implementation still lags behind native integrations in some significant areas.
Thread-based devices:
- Nanoleaf Essentials light bulb and LED light strip
- Eve Home smart plug
Wi-Fi devices:
- Sonoff MINIR4M inline switch
- Zemismart ZME2 dual inline switch
- Wiz light bulbs
- Tapo P110m smart plug
Most devices initially required their native app for firmware upgrades (although the new Eve device updated without it), and there were many features only accessible via native apps (even where the features are in the Matter standard).
In particular none of the switches had separate switch and relay parts for detached operation via Matter bindings, although the Sonoff does support detached mode via the native app, and the Zemismart had the Binding cluster but I couldn't get it working.
Continue reading Hands on with Matter and Thread(11 min read)